- Siguenos:




Primera parte
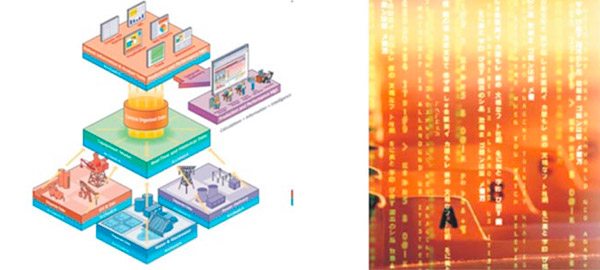
La revolución digital ha hecho posible que la información digitalizada sea fácil de capturar, procesar, almacenar, distribuir y transmitir. Según los investigadores Mitra y Acharya, en el libro escrito el año 2003 titulado “Minería de datos: Multimedia, computación blanda y bioinformática”, con el importante progreso en informática y en las tecnologías relacionadas y la expansión de su uso en diferentes aspectos de la vida, se continua recogiendo y almacenando en bases de datos gran cantidad de información. Según Moine y sus colegas, en el artículo escrito el año 2011 titulado “Estudio comparativo de metodologías para minería de datos”, los esfuerzos en el área de la minería de datos se han centrado en su gran mayoría en la investigación de técnicas para la explotación de información y extracción de patrones, tales como árboles de decisión, análisis de conglomerados y reglas de asociación. Sin embargo, se ha profundizado en menor medida el hecho de cómo ejecutar este proceso hasta obtener el “nuevo conocimiento”, es decir, en las metodologías. Las metodologías permiten llevar a cabo el proceso de minería de datos en forma sistemática y no trivial. Ayudan a las organizaciones a entender el proceso de descubrimiento de conocimiento y proveen una guía para la planificación y ejecución de los proyectos. Algunos modelos conocidos como metodologías son en realidad un modelo de proceso: un conjunto de actividades y tareas organizadas para llevar a cabo un trabajo. La diferencia fundamental entre metodología y modelo de proceso radica en que el modelo de proceso establece qué hacer, y la metodología especifica cómo hacerlo. Una metodología no solo define las fases de un proceso sino también las tareas que deberían realizarse y cómo llevar a cabo las mismas. Las metodologías de minería de datos más importantes son: (1) “Extracción, Selección, Exploración, Modelado y Valoración (ESEMV). (2) Proceso Estándar para la Industria Cruzada (PEIC) y (3) Metodología Microsoft.
En palabras de Flores, en la tesis de maestría escrita el año 2009 titulada “Detección de patrones de daños y averías en la industria automotriz”, el Instituto SAS fue el desarrollador de la metodología ESEMV, a la cual define como el proceso de selección, exploración y modelado de grandes cantidades de datos para descubrir patrones de negocio desconocidos. El nombre de esta terminología es el acrónimo correspondiente a las cinco fases básicas del proceso. El proceso se inicia con la extracción de la población muestral sobre la que se va a aplicar el análisis. El objetivo de esta fase consiste en seleccionar una muestra representativa del problema en estudio. La representatividad de la muestra es indispensable ya que de no cumplirse invalida todo el modelo y los resultados dejan de ser admisibles. La forma más común de obtener una muestra es la selección aleatoria, es decir, cada uno de los individuos de una población tiene la misma posibilidad de ser elegido. Este método de muestreo se denomina muestreo aleatorio simple. La metodología ESEMV establece que para cada muestra considerada para el análisis del proceso se debe asociar el nivel de confianza de la muestra. Una vez determinada una muestra o conjunto de muestras representativas de la población en estudio, la metodología ESEMV indica que se debe proceder a una exploración de la información disponible con el fin de simplificar en lo posible el problema para optimizar la eficiencia del modelo. Para lograr este objetivo se propone la utilización de herramientas de visualización o de técnicas estadísticas que ayuden a poner de manifiesto relaciones entre variables. De esta forma se pretende determinar cuáles son las variables explicativas que van a servir como entradas al modelo.
La tercera fase de la metodología consiste en la manipulación de los datos, con base en la exploración realizada, de forma que se definan y tengan el formato adecuado los datos que serán introducidos en el modelo. Una vez que se han definido las entradas del modelo con el formato adecuado para la aplicación de la técnica de modelado, se procede al análisis y modelado de los datos. El objetivo de esta fase consiste en establecer una relación entre las variables explicativas y las variables objeto del estudio, que posibiliten inferir el valor de las mismas con un nivel de confianza determinado. Las técnicas utilizadas para el modelado de los datos incluyen métodos estadísticos tradicionales, tales como análisis discriminante, métodos de agrupamiento, y análisis de regresión, así como técnicas basadas en datos tales como redes neuronales, técnicas adaptativas, lógica difusa, árboles de decisión, reglas de asociación y computación evolutiva. Finalmente, la última fase del proceso consiste en la valoración de los resultados mediante el análisis de bondad del modelo o modelos contrastados con otros métodos estadísticos o con nuevas poblaciones muestrales.

| Portada de HOY |
|
| Sociales |
SÉPTIMO ARTE LATINOAMERICANO EN LA CINEMATECA BOLIVIANA
Julio Prieto, agregado Cultural del Perú; Tatiana Vargas, encargada de Negocios de Costa Rica; Daniel Beltramo, agregado Cultural de Argentina; Verónica Mora, agregada Cultural del Ecuador; Juan José Di Sevo, ministro uruguayo; Estephania Rada, de la Cinemateca, y Ximena Aguirre, agregada Cultural de Venezuela. CAMPEONATO DE PESAS EN EL CLUB ALEMÁN
El ganador exhibe su certificado junto a la capitana del Club, Jessie Maderholz, Sasha Guedes y el presidente del Club, Klaus Bauer. |
| 1 Dólar: | 6.96 Bs. |
| 1 Euro: | 8.94 Bs. |
| 1 UFV: | 1.78608 Bs. |
| Impunidad |










